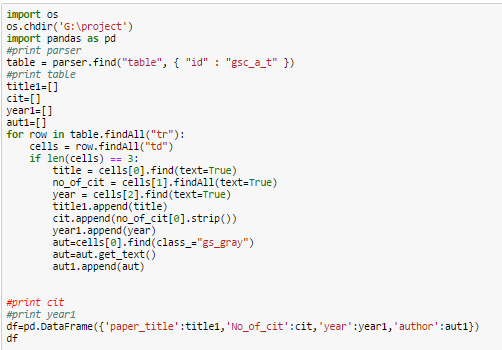
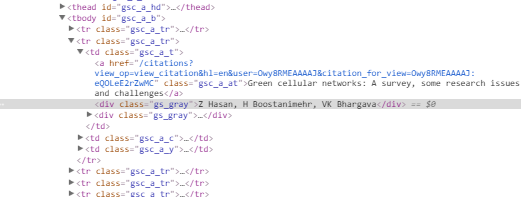
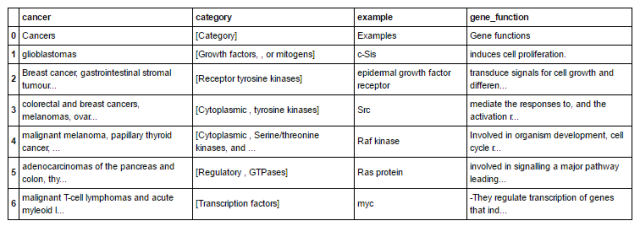
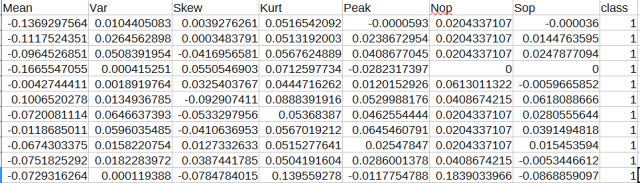
Lets say, we have 112 Features for classifying two classes, All the features might not be needed for correlated with class. The procedure which is employed to get rid of less discriminative features is called Feature Reduction.
PCA, ICA and many other techniques are available, Let try doing the same in Random Forest. Let make use of feature ranking that is obtained from random forest.
Procedure:
Divide features into sets of data.
- In round 1, let’s select 42 features from 112 features.
- In round 2, let’s select 18 features from 42 features obtained from round 1.
- In round 3, let’s select 9 features from 18 features obtained from round 2.
Round 1:
In previous post, we had discussed about, how to split a large data frame into subset dataframe.
- Let’s split dataframe to 14 sub dataframes, with each sub dataframe having 8 features.
Note: Each sub dataframe has 189 instances (data has: vertical first half class1, and last half class 0; and last column is class column)
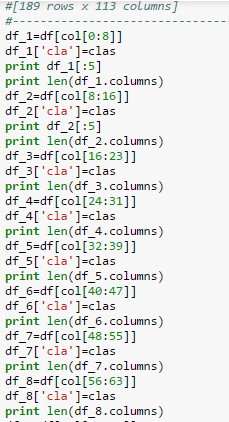
Fig: Code for splitting dataframe into 14 subsets
Dataframe splitted into subsets and class column is added to each subset.
Classification done with Random forest, and best features are selected and saved as list.
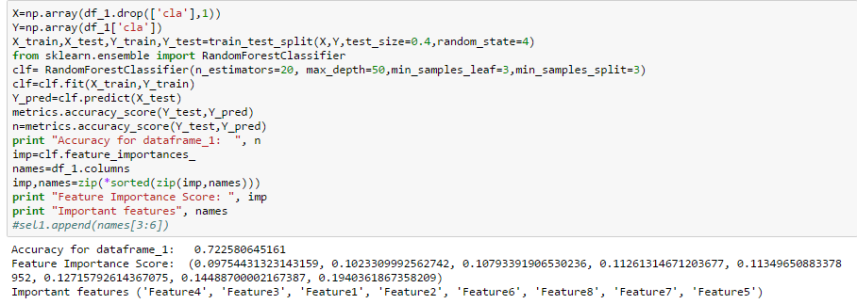
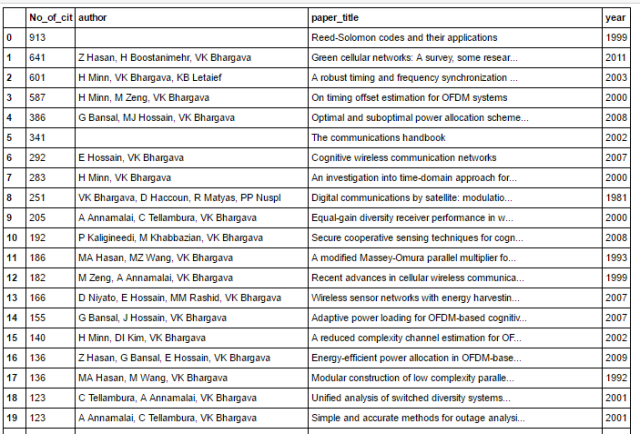
The above code classifies and gives list of important features in list. The last three features are high ranked features and they are selected and appended to list called “sel”. The accuracy of each subset is also appended.
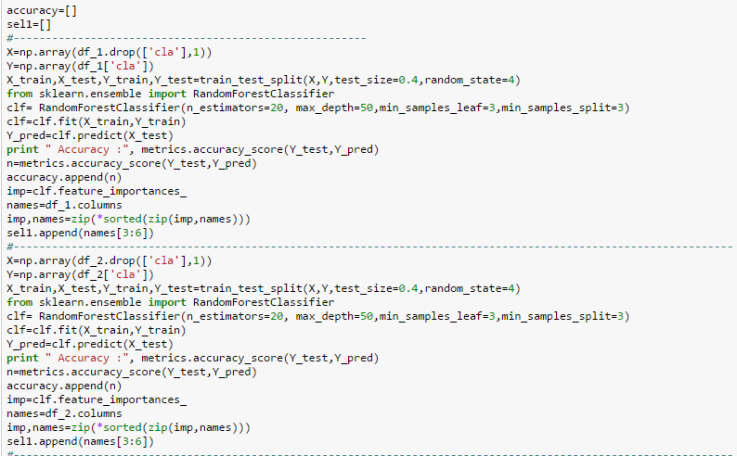
Likewise the classification is done for all 14 datasets, and top three features in each dataset and accuracy of classification is appended in “accuracy” and “sel1” list respectively.
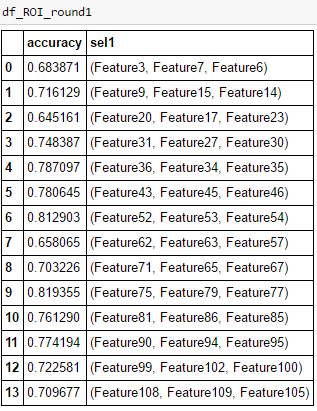
Fig1: Features selected from Round1
Round 2:
The Features displayed in sel1 column can be made a list, and again features can be filtered in the round 2, and round3 to finally get 9 features.
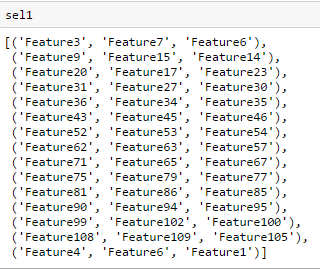
Fig2:Features selected from Round1
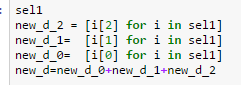
Fig3: Code for obtaining list from list of list.
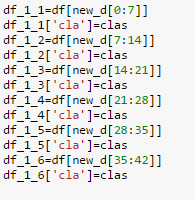
Fig4: Code for splitting dataframe into second subsets for Round2 analysis.
Repeat the same steps for round2, and filter down features from Round2 to Round3.
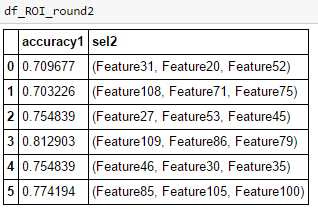
Fig5: Round2 selected Features

Fig6: Round3 selected Features
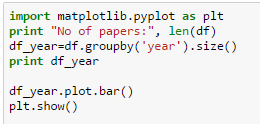
By using the features obtained from Round3, and carefully tuning parameters in Random Forest classification accuracy as high as 85% was achieved.